
I made the interpreter by ripping the parser out of the compiler, making it produce an AST instead of assembly code, and writing a recursive evaluator for the AST. It was way less work than writing the Lisp interpreter, and it runs programs about 100x faster than the Lisp interpreter.
I don't know why it didn't occur to me to write a SLANG interpreter sooner. Possibly I thought it would be too much trouble, and only after I wrote the Lisp interpreter did I realise that it would not. There's also the weirdness that SLANG code does not have automatic memory management, and I don't know if I've ever seen an interpreted language that requires manual memory management (maybe FORTH, if you squint?). SLANG just doesn't seem a natural fit for being interpreted.
But it turns out that if you don't have to bother with a garbage collector, and you don't care if the computer crashes when the stack overflows, then writing the interpreter is quite straightforward. And these arguably aren't even defects of the interpreter, because the compiled language works exactly the same way. It's up to the programmer to make sure the program is not going to leak memory or run out of stack space.
The source code is currently slightly longer than that of the compiler:
$ wc -l slangc.sl slangi.sl
1230 slangc.sl
1293 slangi.slBut this is only because I have reimplemented some of the more important parts in assembly language. Originally it worked out slightly shorter than the compiler.
If you like, you can watch a video of me using the interpreter to solve Advent of Code 2018 day 4.
Usage
The interpreter is available in the online emulator, just run your program with slangi foo.sl, for example:
$ cat foo.sl
printf("Hello, world!\n", 0);
$ slangi foo.sl
Hello, world!It overrides the cmdargs() system call so that arguments passed on the command line (e.g. slangi foo.sl arg1 arg2 arg3) come out the same way they would do in the equivalent compiled program.
AST representation
Each node of the AST is a pointer to an object whose first element is a pointer to the function that evaluates the object. For example, you could create a node that returns a constant value like:
var EvalConstNode = func(node) {
return node[1];
};
var ConstNode = func(val) {
var node = malloc(2);
node[0] = EvalConstNode;
node[1] = val;
return node;
};
The objects are then evaluated with a helper function called eval:
var eval = func(node) {
var f = node[0];
return f(node);
};Hopefully you can see that eval(ConstNode(42)) will return 42.
We can easily make a node for if (cond) thenblock else elseblock that tests its condition, evaluates its "then" block if the condition is true, and evaluates its "else" block (if any) otherwise:
var EvalConditionalNode = func(node) {
var cond = node[1];
var thenblock = node[2];
var elseblock = node[3];
if (eval(cond))
eval(thenblock)
else if (elseblock)
eval(elseblock);
};
var ConditionalNode = func(cond, thenblock, elseblock) {
var node = malloc(4);
node[0] = EvalConditionalNode;
node[1] = cond;
node[2] = thenblock;
node[3] = elseblock;
return node;
};Composition of these different node objects gives us an object tree that represents the program structure, and calling eval() on the root node results in evaluation of the entire program.
Calling convention
Calling convention on SCAMP is that the function arguments are pushed onto the stack and the return address is passed in the r254 pseudoregister (i.e. 0xfffe).
(Why isn't the return address also passed on the stack? Because that can't be done in 8 cycles, which is the upper limit for a single instruction. In practice return addresses are often "manually" stashed on the stack, to allow nested function calls to work).
A "function pointer" in SLANG is just a number like any other. (In fact, SLANG doesn't really have types at all: every value is a 16-bit word). This means that when our interpreted program calls a function, all we get to know is what number it is trying to call.
This presents 2 problems:
- When our interpreted code makes a function call, we need to obey the calling convention in case it is calling out to a compiled function (e.g. in library code).
- Sometimes library code can call back into our interpreted code, so our interpreted functions need to be callable with ordinary calling convention.
I made the FunctionDeclaration parser create a machine-code shim for the function. The shim calls a function evaluator, passing it a pointer to the arguments, a pointer to the list of argument names, and a pointer to the AST for the function body. The function evaluator sets up the new local scope and uses eval() to evaluate the body.
This way each function declared in the interpreted code still has its own entry point, and can still be called with ordinary SCAMP calling convention, which means compiled functions and interpreted functions can interact freely.
break, continue, return
break, continue, and return are challenging, in that they can require jumping a long way up the interpreter's call stack. It would be most inconvenient if every single evaluator had to have special code to notice when an eval() call is asking for a break, continue, or return, and manually pass the condition upwards.
My solution was to use longjmp. (I like to say that longjmp is my goto).
The evaluator for a LoopNode uses setjmp to set globals for BREAK_jmpbuf and CONTINUE_jmpbuf. The evaluator for a BreakNode simply longjmps to the BREAK_jmpbuf:
BreakNode = func() {
return [EvalBreakNode];
};
EvalBreakNode = func(n) {
longjmp(BREAK_jmpbuf, 1);
};
EvalLoopNode = func(n) {
...
setjmp(CONTINUE_jmpbuf);
if (!setjmp(BREAK_jmpbuf)) {
while (eval(cond))
if (body) eval(body);
};
...
};There is a similar setup in the function evaluator for writing a RETURN_jmpbuf.
So whenever a BreakNode is evaluated, it longjmps to the BREAK_jmpbuf which magically puts control straight back into EvalLoopNode, regardless of how many other stack frames are in the way.
There is a small amount of book-keeping to make sure nested loops and nested function calls unwind correctly, but overall I think it is quite elegant.
I reused the longjmp implementation from the kernel. All it does is that setjmp copies the stack pointer and return address into the jmpbuf, and longjmp restores them. The result of a longjmp is that the setjmp call returns a second time. The first time (when the jmpbuf is created) it returns 0. When returning because of a longjmp, it returns the value that was passed as an argument to longjmp (1, in the example above).
Benchmarking
Using the same benchmark program as last time, we can add "SLANG (interpreted)" to the chart:
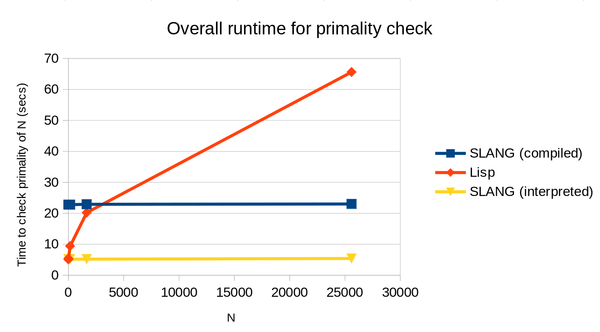
And we see that we get the best of both worlds! The growth rate as N increases is comparable to that of compiled SLANG code, but the fixed overhead is comparable to that of Lisp, because we don't have to waste time on the compiler and assembler. The runtime is almost constant in this example because it is dominated by the fixed overheads.
We can get a better idea of the differences between the compiled and interpreted SLANG implementations if we compare the overall runtime for a more complex program. This one naively calculates primality of all integers from 2 to N:
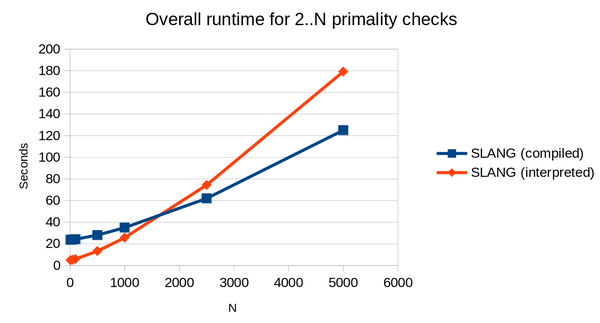
And now we see that the interpreted code only becomes a worse proposition than the compiled code once the overall runtime exceeds about 45 seconds.
In general I've observed that the interpreted code runs about 2x-4x slower than the compiled code, but we get to save spending 20+ seconds on compilation.
In my Advent of Code video, the solution for part 2 ran in 1m35s in the interpreter. The compiler took 52 seconds and the compiled code took 38 seconds, for a total of 1m30s for the compiled version, so the compiled version won, but only slightly. On the sample input the interpreted version is a big win.
I think this is actually a much better outcome than Lisp would have been, even if the Lisp interpreter was fast, because it means for any given program I get to decide whether I want it to start up quickly to test small changes (use the interpreter) or whether I want it to run as fast as it possibly can on larger inputs (use the compiler), without having to make any changes to the source file.
Memory overhead
Speed isn't the only reason to prefer the compiler. The interpreter is the largest SCAMP binary yet made, weighing in at almost 25K words (the next biggest is the assembler at 20K). Loading the interpreter basically halves the size of your Transient Program Area before you've even started, and you also have the size of the AST on top of that. For quick tests on small inputs that's not usually a problem, but it is something to bear in mind.