
Lisp has been the most recent step in my search for the ultimate SCAMP programming environment. Unfortunately what I have so far is so slow that it's probably another dead-end. It's about 300x slower than compiled SLANG code.
You can play with it in the emulator. Just type lisp at the shell to get into the Lisp REPL.
(Note that I think I recently made some bugs; it seems to try to evaluate spurious code after it completes evaluating larger forms. I'm not going to bother fixing it because I'm probably not going to use it, but if you play with it and think it acts funny... that's why).
Types and garbage collection
Almost everything in Lisp is made of "cons cells". A cons cell is just something that has 2 fields, that can each point to either NIL (the empty list), or to another cons cell. The 2 fields are called car (contents of address register) and cdr (contents of decrement register) due to the IBM 704 which Lisp was originally created for in the 1950s.
In practice we want to be able to store things other than cons cells (e.g. we want to represent integers without some complicated encoding made out of cons cells). For this reason I have established the convention that if the car field is nonzero, but less than 256, then it is a type identifier rather than a pointer to a cons cell. This is perfectly safe because the first 256 addresses in SCAMP memory are the bootloader ROM, so there can never be actual cons cells created at those addresses. Where the car field indicates that a cell has a non-cons-cell type, the cdr field is specific to that type. For integers it contains the raw integer. For strings it contains a pointer to the string, etc.
| type | id | notes |
|---|---|---|
| NIL | 0 | used for empty list and "false" |
| SYMBOL | 2 | cdr points to interned string containing symbol name |
| INT | 4 | cdr is raw integer value |
| BIGINT | 6 | unimplemented |
| VECTOR | 7 | unimplemented |
| STRING | 10 | cdr points to string; only string constants supported for now |
| HASH | 12 | unimplemented |
| CLOSURE | 14 | cdr points to cons structure containing function body, argument names, and parent scope pointer |
| BUILTIN | 16 | functions implemented in SLANG, cdr is SLANG function pointer |
| PORT | 18 | essentially a boxed file descriptor |
| CONTINUATION | 20 | not accessible within the Lisp programs, just used for trampolined style |
| MACRO | 22 | similar to CLOSURE, except the value returned is then itself evaluated (this is not the correct way to implement Lisp macros, because you pay the macro execution cost every time you call it, instead of only once) |
My Lisp interpreter uses a mark-and-sweep garbage collector. In order to be able to "mark" a cons cell, we need some way to store 1 bit of information in the cell. Given that each cons cell contains 2 fields, I established the convention that they are always allocated at even addresses. That way, any pointer to a cons cell is always an even number. If we also make sure that all of the type identifiers are even numbers, then every value that can legitimately be stored in a car field is an even number. We can now use the least-significant bit of the car field to let the garbage collector mark the cells that are accessible from the environment.
So the garbage collector looks in the current scope, and every scope in the call stack, and recursively marks all accessible cons cells as "used". Having done this, it sweeps through the arenas that cons cells are allocated in, frees any that are now unused, and clears the mark bit from cells that are still used.
The garbage collector is invoked at the top of the EVAL() loop if there are fewer than 100 free cells. That ensures there are always enough cells to do the work of one EVAL() iteration. This is an idea that I got from ulisp's garbage collector.
Before I came across the ulisp example, my first idea was that I would invoke the garbage collector from cons() if ever anything tried to allocate a cell and there were 0 free cells available. The problem with that approach is that some parts of the interpreter need to construct objects consisting of several cons cells, and it's bad if the garbage collector frees some of the cells halfway through constructing an object that isn't yet linked into the program's environment. Having a single defined place that the garbage collector can be invoked from makes reasoning about its semantics much easier.
Trampolined style
The natural way to write the interpreter is to make EVAL() recursive. Unfortunately this means you need arbitrarily-large amounts of stack space in order to support arbitrarily-deep recursion, and we don't want to have to make a commitment ahead-of-time as to how much space we allocate for the stack and how much for the heap.
My solution for this was to make EVAL() iterative, and store the Lisp program's "call stack" in a linked list made up of cons cells. This is quite pleasing in many ways because it helps to ensure that every reachable object is reachable from the cons cells in the program's environment.
Some parts of the interpreter need to call EVAL() on some Lisp form, and then do something with the computed value. The solution for this is to push onto the call stack a "continuation", which is just a SLANG function pointer and some associated state. Every time EVAL() finishes evaluating a Lisp form, it pops the calling continuation off the stack and passes control to it. I found out later that this is called "trampolined style". It is quite a flexible way to handle control flow, and for example it makes tail-call optimisation very easy.
Unfortunately it makes for control flow that is extremely difficult to understand. But I think it's just complicated because it's complicated. It's not obvious that there is an elegant way to implement it.
Benchmarking
I wrote a short program to test primality of an integer, in both SLANG and Lisp. (It does it the stupid way: just test for divisibility by odd numbers up to sqrt(n)).
Here's a chart showing overall runtime for both the SLANG and the Lisp version, with the time for the SLANG version including the time it took to run the compiler, and the time in all cases being measured from hitting enter at the shell prompt to getting back at the shell prompt (i.e. including process switching overhead, which occurs twice if we need to run the compiler).
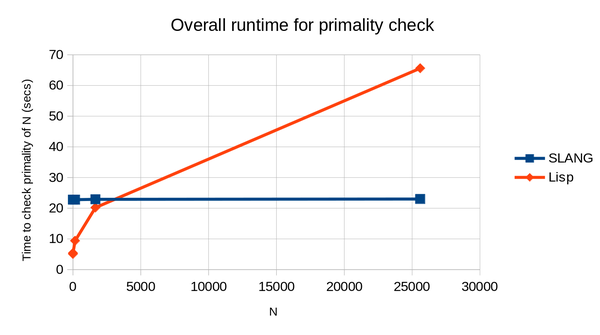
The time to run the SLANG program is dominated by the time it takes to compile it, in all tested inputs.
You can see that even with compilation time included, running the Lisp program takes longer as soon as we get up to about N=3000. In other words, if you have a program that does ~30 iterations of a trivial loop, you're better off writing it in SLANG even though it takes 20 seconds to compile.
If you subtract out the compilation time and process-switching time, then the largest input I tried takes about 60 seconds in Lisp versus 0.2 seconds in SLANG. So the Lisp interpreter is about 300x slower. I put this down to the complicated trampolined style, and the fact that every operation involves allocation of multiple cons cells.
What's next?
I'm still after a better SCAMP development workflow. My main issue is that it takes too long to compile a program to test small changes.
I think I've ruled out both Lisp and my interactive SLANG REPL that compiles each line of code as it's typed. Lisp because it's too slow, and the SLANG REPL because it's too much of a footgun.
Maybe the next idea is to write a SLANG interpreter. That way I could run the program in the interpreter on small inputs, and only when satisfied that it is correct do I need to invoke the compiler in order to make it run faster. This has the benefit that we don't need to pay the compilation time on small inputs, but we get to use exactly the same program to get the fast runtime on large inputs.
Probably the way to do this is to rip the parser out of the compiler, have it construct an abstract syntax tree, and then interpret the AST with a straightforward recursive evaluator. I think the overhead of the trampolined style is too much to be worth paying, and besides SLANG code doesn't tend to recurse anywhere near as aggressively as Lisp code.
Unlike with the Lisp interpreter, I wouldn't try to make it "safe". SLANG code is inherently unsafe. I think if the interpreted program tries to do something that would run off and crash in the compiled code, it's perfectly fine for the interpreter to run off and crash as well. That means we don't need the interpreter to waste time on type checks and bounds checks. It'll just straightforwardly do the same thing that the compiled program would do, for example if you try to call an uninitialised function pointer.