Last modified: 2024-12-06 23:14:11
< 2024-12-05 2024-12-07 >On 2024-11-10 I purchased Stuart Harrison's "John Harrison's Contrivance" on Amazon, but it never arrived. I apparently forgot about it, I've just opened a complaint on the Amazon UI.
On 16th of April this year I emailed Stuart Harrison to ask if he knew where I could get the book, and received no reply.
On 28th of November this year I again emailed Stuart Harrison, just in case he had missed my first email, and yesterday he replied to me, with a PDF of his book! What a result!
He made the mistake of asking about my interest in Harrison and whether or not I make clocks so I have sent him probably much more text than he wanted to read.
The PDF is broken up into 3 pieces that combined run to 325 pages. I haven't yet decided whether I'll print these out myself or get a print-on-demand service to do it.
First thing is re-run the clock now that I've straightened up the balance spring, adjusted the pivots, etc.
I've re-adjusted the pallets to suit, because the spring attachment got moved around.
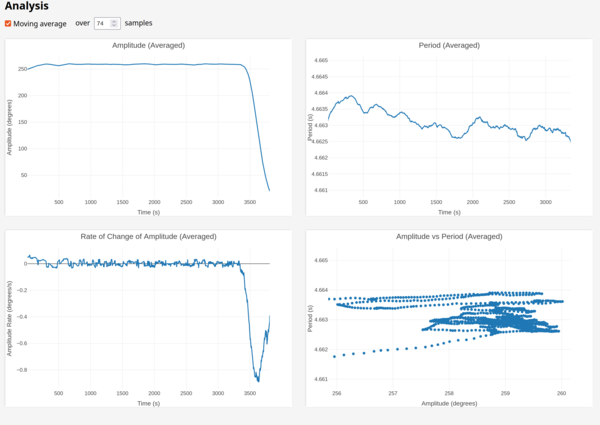
Oops, while I was writing my essay to Stuart Harrison I let it run out of string so the scale on the charts got ruined!
I have manually zoomed in here to the relevant sections on the right 2 plots:
So that's within 1.5 milliseconds, which is better than before but maybe not by an awful lot.
The relationship between amplitude and period is basically flat, which is good, but then I don't know why the period was dropping over time.
The environmental plot shows:
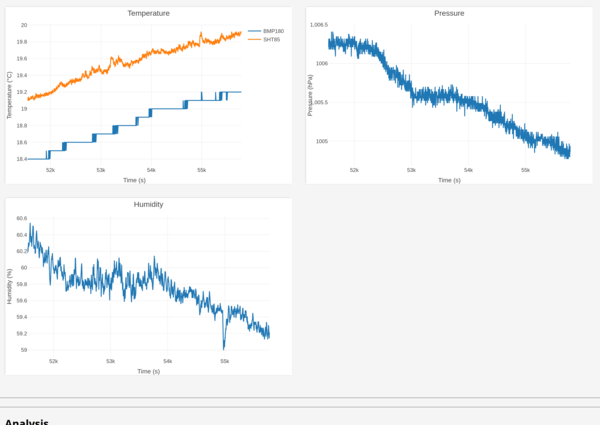
So temperature was increasing; humidity and pressure decreasing.
Wouldn't we expect heat to make the clock run slower, not faster? Could be unrelated.
I want to make the winding drum longer so that I can make use of longer string on the drive weight. I think 4x longer, because currently the string only reaches halfway to the floor, plus I want to add a pulley.
I made it twice as long, and put the coils closer together, and now we have 14.5 turns instead of 4 turns, so about 3.6x as long.
OK, longer drum is installed, and I've got enough string to fill it. First I'll run it with no pulley just to confirm the clock still works as before, then I'll try out the pulley.
The torque at the escapement will be slightly less, because I have swapped a short shaft and a long shaft in order to accommodate the longer winding drum. I can account for this by moving the remontoire weight further out though. I will try to set it to run at about 255 degrees like it did before.
One issue I've identified is that with the winding drum hanging off the back of the frame, as the weight runs down it moves further back, which means the weight acts to splay the frame open more when it is further down than when it is higher up, which could explain why there is a "trend" in the amplitude and period over time.
It's just occurred to me that doubling the drive weight, for use with the pulley, will also splay the frame open more.
So far the longer winding drum is looking like a success.
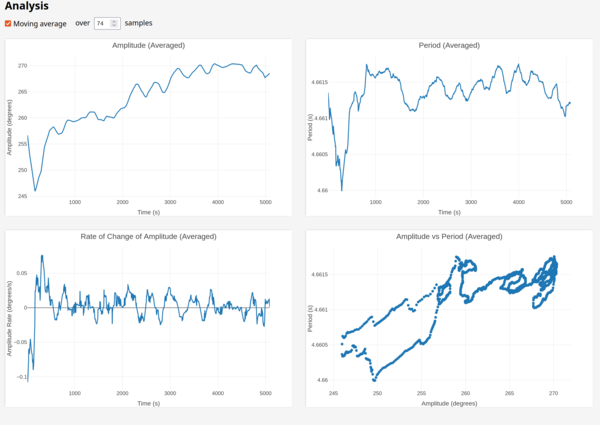
That's the longest trace yet, and once it settled down it stayed within 1 millisecond.
Ugh, I did it again. I walked off and didn't catch it at the end of the run, so here the right 2 plots are again zoomed in:
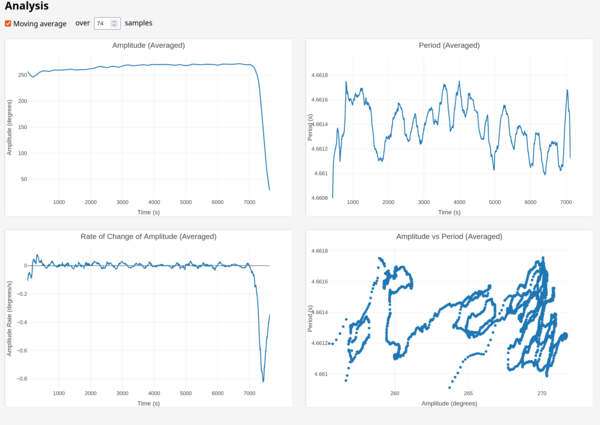
I had a dream that the hunting amplitude problem was caused by the ball bearings!
That would explain why it is approximately some ratio of the escape wheel rotation, but not quite the same as any actual component, and also why the error margin is so wide: it's not actually geared, it just rolls.
I think maybe it actually does reset it, but it doesn't actually redraw until there's new data?
That was it, because plots.js reset() clears out plotStates, plotStates gets recreated
at the next updateAll() call, but then looks like there's been no changes so the chart
doesn't get redrawn. Fixed now.
I think this happens when we start dropping the oldest datapoints. Possibly because velocity can't be calculated until we have N positions, they end up out of sync because we drop position points before we drop velocity points.
I wonder what to do about that.
This one is because if the clock isn't running for an extended period of time then we
get multiple overflows of micros(), but we only account for one overflow.
So this problem will go away when the clock is running permanently. But apart from that, I could work out how many overflows occurred by looking at the wallclock time elapsed since the last datapoint.
And I'll also want to apply a "rate" to the ESP32 clock to keep it synced with NTP or whatever, so that would help as well. I was thinking that the rate could be basically an exponential moving average of the ratio of the ESP32 clock to the Linux clock, and then we make sure the Linux clock syncs with NTP. We can plot the applied rate in the UI to make sure we're not doing anything crazy. Applying a rate that smoothly adjusts means we don't have any step changes in timestamp around the time we re-sync.
But if there's ever more than 60 (30? 10? 1?) seconds between datapoints from the ESP32, then we can just make a step change re-sync of the ESP32 time to Linux time.
60 seconds will easily be fine, because the micros() won't wrap until 71.58 minutes, or half
that if unsigned.
OK, I did that, and I also made it start reporting (but not yet correcting) the timestamp drift. It's not yet obvious whether the bulk of the error comes from the ESP32 or from the Pi, but it looks like this:
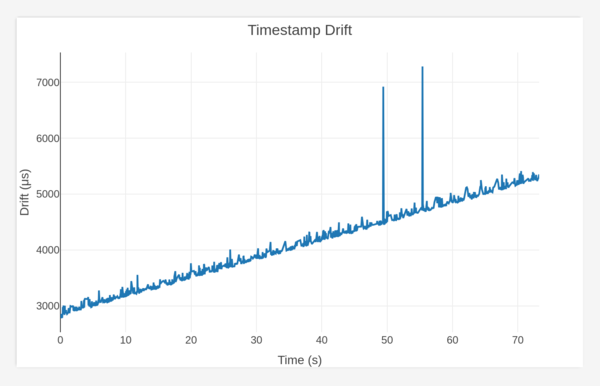
It drifted by about 2 ms in 1 minute, which is probably more than I would have guessed. And I think an exponential moving average of this would work very well. I don't know whether to try to throw out the big outliers, or just let the averaging work them out.
I think they might happen when there are 2 datapoints in very quick succession, maybe?
I can make the Go code grab the current Pi timestamp immediately after reading from the serial, that would remove any timing variation in the intervening code.
I restarted systemd-timesyncd to trigger an immediate re-sync, and this
happened:
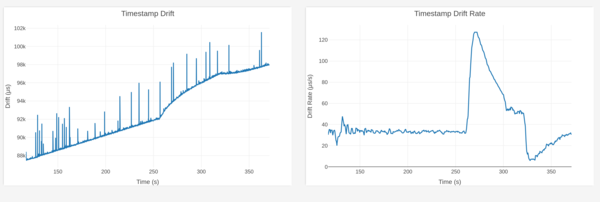
I restarted it at about 260 seconds.
It looks like there are 2 different syncs applied here, one at 260 seconds where it thinks it needs to run faster, until about 305 seconds. Then for maybe 15 seconds it stays still, then at about 320 seconds it starts running slow for about 10 seconds, then it goes back to normal?
And it looks like the sync is applied as a skew instead of a step change. That is probably helpful for me overall.
The way I'm calculating the rate is by looking at a window of the last 200 datapoints, I take the index of the minimum drift value in the first 100, and the minimum drift value in the second 100. Then compare the implied elapsed time on the ESP32 clock (y value + x value) with the elapsed time on the Pi clock (x value) between those 2 points to find the rate.
The reason to take the minimum drift value is because jitter on the Pi side always adds to the drift but never subtracts from it. By taking the minimum values we are maximising the chances of picking a datapoint with minimal Pi-side overhead.
The drift is basically bounded below by a straight line (at least at short time-scales), and jitters above this line, so all we are really trying to do is work out the gradient of that line.
The jitter above the line is not something we need to account for, because we already get timestamps from the ESP32. The rate is meant to work out how much the ESP32 time is drifting from "real" time. I don't really care how much jitter there is on the Pi side, because Pi timestamps are only used for calculating the ESP32 rate. The ESP32 timestamps are used for the actual calculations.
As long as we can apply an accurate rate to the ESP32 clock then the Pi jitter is of no consequence.
There is a big storm coming, I got a government "RED" alert pop up on my phone. If it is anything like Storm Bert it will turn out to be much ado about nothing.
I have left a program running on the Raspberry Pi to log pressure data to a CSV file so that we can see how it varied in the run up to the storm, and afterwards.
And just after I started capturing the CSV, I had this in the web interface:
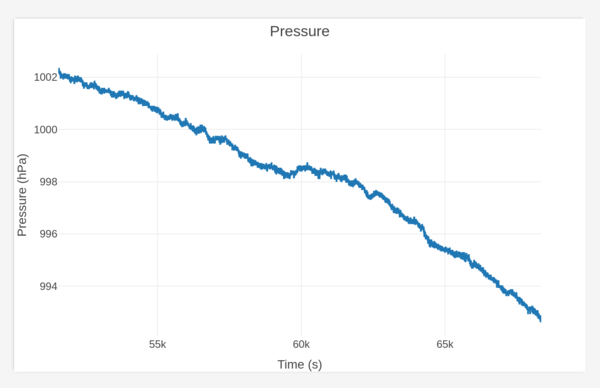
At 20:26.