Last modified: 2024-10-07 09:03:47
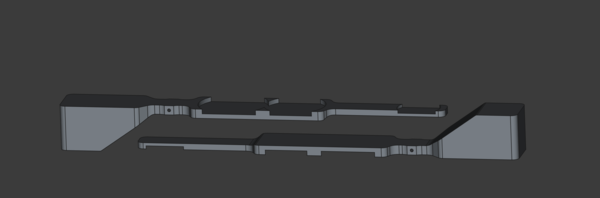
< 2024-10-05 2024-10-07 >Tiling the parts like this, we get almost 2x the material utilisation:
I got the idea from a photograph in this blog post: https://www.marshallhaas.com/post/the-wild-story-of-how-i-made-1-036-175-in-67-days-during-covid

FreeCAD Addon Manager has a macro called "Center Of Mass", https://wiki.freecad.org/Macro_CenterOfMass - really good.
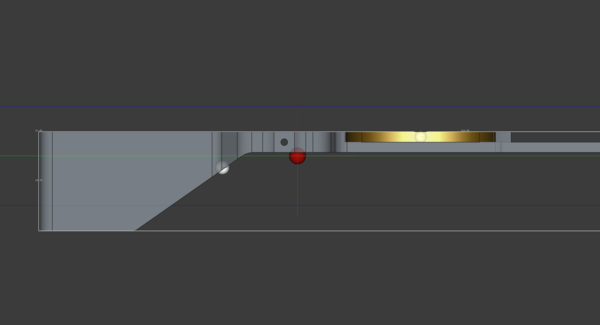
The red sphere in the middle is the combined centre of mass of the beam and coin.
To the right of the pivot means the counterweight is too light. I need the counterweight to be too heavy so that I can calibrate it by drilling material out of the counterweight.
If I balance it in CAD with a small hole drilled into the counterweight, then it should be about right in reality, no?
Here we go:
https://www.youtube.com/watch?v=oFfVt3S51T4
Up to 0:52:
For tab auto-complete to work well it needs to be fast, which means it needs to be a really small model, trained on the right kind of stuff. Maybe look at shell scripts from GitHub? That's not quite the same, but might be good enough. And obviously fine-tune Llama3.1:8b and run it locally on GPU.
For tab complete you want lots of context input and very few tokens output. "And so, the perfect fit for that is using a sparse model... meaning an MoE model". Where "MoE" is "mixture of experts".
"Design the prompts used for the model so that they're caching-aware". He's saying that because there is very little change from one prompt to the next, you need to be able to not fully re-compute the entire prompt. I still don't really know how that works, I thought the computation totally changed as soon as you added a new token of input, because every token is now in a different place. Need to learn more here. Perhaps he's saying that you try to manipulate the prompt so that most of the tokens are in the same place they were before? And "Reuse the KV cache across requests".
They use a custom model for tab complete, but also a custom model for applying the diffs suggested by the LLMs. I had wondered how that worked, because it doesn't seem like the code snippets produced in the chat box contain enough information to deterministically apply them without some extra intelligence. And it turns out they don't, they actually do use extra intelligence.
Speculation that Claude has got worse because it was trained on Nvidia GPUs but now runs on some AWS chips that might have different rounding errors etc.?
Some talk about agents, how they don't generally work yet for complex tasks but getting close. Suggestion that he would like to give the agent an instruction for a well-specified but complex task, and have the agent go away and solve it, and then provide the solution hours later. So not just writing code, but reproducing the existing bug, testing the proposed solution, etc.
< 2024-10-05 2024-10-07 >