Last modified: 2023-11-28 00:14:57
< 2023-11-26 2023-11-28 >I'm a bit confused about what sort of magnets I should be using. My notes say the CAD is intended for 8mm by 2mm magnets, but the CAD has a hole that is 6.2mm in diameter.
It wants magnets that are 6mm by 2mm, and they are not quite a press fit so they want a drop of superglue.
Next up is preparing the frame pieces.
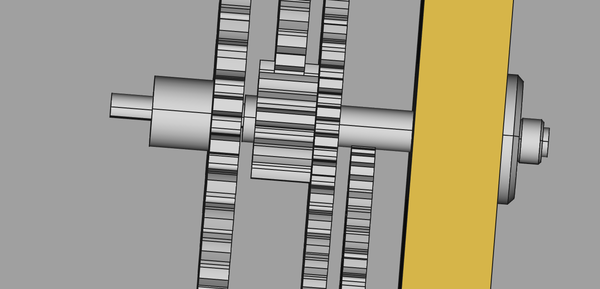
I've made both backplane pieces and assembled the wheels and stepper motor. Mostly looks OK, but the second wheel interferes with the third wheel spacer. The problem also exists in CAD, so it is poor that I didn't already know about this issue:
Also:
So what am I going to do about the spacer? Probably have to make a thinner one. I want a 12.5mm long piece of aluminium or brass, 6mm diameter, with a 5mm bore. While I'm at it maybe I should make all of the spacers this way, as they are shoddy and have cracked.
So the plan is:
I think my ethernet cable is 10m and really wants to be 12m. For now I've strung it up diagonally, but I've ordered a female-to-female plug so that I can extend it with a 2m cable and then pin it up properly.
I've put an MDF top on the computer desk:

And started populating the tool wall:

Update: no ethernet again :(. Even with it plugged in a bit closer to the fusebox. I have one more option to get slightly closer to the fusebox once I have the cable extender, and if that doesn't work then it'll have to be wifi.
I think we can probably do away with the postfix notation, and turn the AST into the NFA. For that matter, it is probably easy enough to lose the AST and parse straight to the NFA.
But for now let's just amalgamate regex and regex.tree-broken so that we parse a normal regex
into a tree and then turn the tree into an NFA that we can run.
I've put the previous regex program in regex.postfix-with-capture.
Actually let's not get ahead of ourselves. I'm going to turn the AST into postfix first.
Turning the tree into postfix is pretty trivial, it turns out. However my capturing isn't working, I was already a bit suspicious it was wrong, need to rethink it.
This series implements capturing in a NFA: https://www.abstractsyntaxseed.com/blog/regex-engine/implementing-a-nfa
He evaluates the NFA with backtracking :(. So he has missed Thompson's key contribution.
Even https://en.wikipedia.org/wiki/Thompson's_construction talks about the method of turning a regex into
an NFA, rather than the method of evaluating the NFA, but it is the O(nm) method of evaluating the NFA that
is most important!
Rust has a regex engine called PikeVM, which is under the regex_automata::nfa::thompson package (? namespace? whatever),
and supports capturing groups.
Apparently this is all based on re1: https://code.google.com/archive/p/re1/
So this project contains a thompsonvm() as well as a pikevm(), and it looks like the thompsonvm()
supports capturing as well. Let's try and understand.
Ah, I misunderstood. The project has a general-purpose form for capturing groups, and thompsonvm() uses this
method to indicate whether or not the string matched the regex. It doesn't track capturing groups.
So let's look at the pikevm(). It is very short. Oh, Russ Cox has a web page about this as well:
https://swtch.com/~rsc/regexp/regexp2.html (and, wow, what a great web page it is).
Submatching can be implemented in both backtracking and non-backtracking VMs. (Code doing this dates back to 1985, but I believe this article is the first written explanation of it.)
Aha, here is the key piece of information I was looking for:
In Thompson's VM,
addthreadcould limit the size of the thread lists to n, the length of the compiled program, by keeping only one thread with each possible 0PC. In Pike's VM, the thread state is larger—it includes the saved pointers too—butaddthreadcan still keep just one thread with each possible PC. This is because the saved pointers do not influence future execution: they only record past execution. Two threads with the same PC will execute identically even if they have different saved pointers; thus only one thread per PC needs to be kept.
So the plan is we parse the regex into a tree, then turn the tree into VM code and then evaluate the VM.
In SCAMP the VM code could ideally be machine code.
For now I'll just try to implement the pikevm() method.
Great! Got it working in regex.pikevm. Very good. It is 250 lines of perl,
but it could probably be a lot shorter, especially in SLANG because we'd collapse the hashes
into something less verbose.
The 250 lines are:
And I'm pretty sure we can skip the AST step, and turn the regex straight into a VM. I think this is good progress.
While thinking about the regex stuff I had the idea that maybe the interpreter could do more actual
compilation, as a starting point ConstNode would be pretty easy: we'd get rid of EvalConstNode
and make ConstNode compile a custom function to return whatever constant you need.
EvalConstNode was about 5% of runtime in my test on 2023-11-17.
Currently it is:
ld x, r254
push x
ld x, 2(sp)
inc x
ld r0, (x)
add sp, 2
jmp 1(x)
(40 cycles)
Whereas my version would be:
inc sp
ld r0, CONSTANT
ret
(15 cycles)
So the time spent on this would be 15/40 of 5% of total runtime, or about 1.9% of total runtime, saving us 3.1%.
I mean, I've made worse optimisations! Let's do it. And maybe it will pave the wave for even more meaningful JIT compilation.
Ah, damn. Several optimisations rely on checking if
n[0] == EvalConstNode, specifically constant-folding
and constant arguments to function calls. Nothing's
ever easy, is it?
I really need to fix the build process so that a single invocation
of make is enough to build everything.
Well I made it JIT-compile const nodes, but I can't be bothered verifying that it actually gets us the supposed 3% performance improvement.
< 2023-11-26 2023-11-28 >