
Last night, inspired by a comment on HN about creating images with randomised neural nets by mapping inputs (x,y) to outputs (r,g,b), I spent some time trying to train a small neural net to approximate Lenna, the famous image processing test input. The outputs are quite interesting to look at, but don't approximate Lenna very well. But I don't know anything about machine learning, so I think you could do much better than I managed.
If you don't know what a neural network is, maybe start with the Wikipedia page.
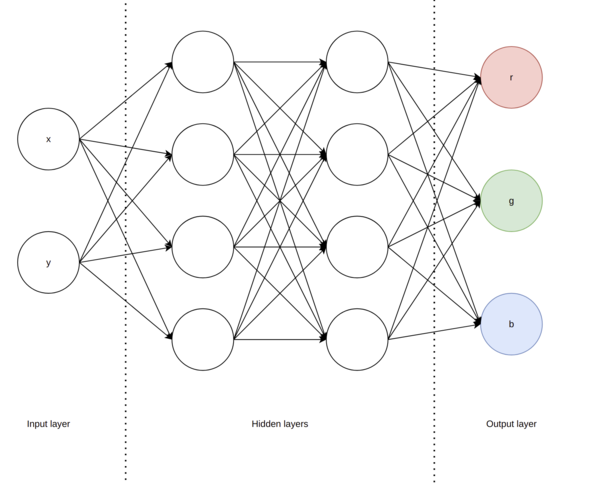
Here's a diagram of the kind of network I was using (mostly a bit bigger than this, but not a lot bigger because training on CPU is slow):
Here's about the best I came up with, after about 3 hours of training, next to the training image (can you tell which is which?):


I had rather hoped for a bit better than this, although the generated image does have quite an interesting aesthetic in its own right.
Here's a video showing how the output improves as training proceeds:
More outputs
Here are some other interesting-looking outputs, not as good as the above. Unfortunately I didn't save the parameters used because I'm not a real scientist.






You can almost make out an outline of a face in a couple of them. If you squint.
These pictures remind me of the kind of nondescript, inoffensive artwork you sometimes find in hotels. It obviously looks like something, but it doesn't look like enough of anything that anybody could possibly be put off by it.
Some of the states from early on in the training, with less detail, are also reminiscent of old Ubuntu desktop wallpapers from around Ubuntu 10.10 to 13.10.


(left: early state from neural net of Lenna; right: Ubuntu 13.10 default wallpaper)
How
I used the AI::FANN perl module, which I think was last updated in 2009, so I imagine the state of the art is now substantially better (probably you'd use TensorFlow if you knew what you were doing?), but I found AI::FANN easy to get started with, and it entertained me for an evening.
The input image's (x,y) coordinates are scaled to fit in the interval [-1,1]. The (r,g,b) values are scaled to fit in [0,1]. (I tried various options and this seemed to work best, but... not an expert, don't know why).
We then create a training set consisting of (x,y) => (r,g,b) for every pixel of the input image, and initialise a neural network with 2 input nodes (x and y), 3 output nodes (r, g, and b), and some number of hidden nodes in some number of hidden layers that we can play with to see what difference it makes. I found I had best results with 3 hidden layers, each with fewer than 20 hidden nodes.
We then run Rprop training over and over again to make the neural network better approximate the function described by the training data, and periodically save the current state so that it can be turned into a video later.
If you want you can use the perl script I was playing with - but it's not really meant for general consumption.
And to turn a directory full of generated images into a video, I used:
$ ffmpeg -r 25 -i %04d.png -c:v libx264 -vf scale=800x800 out.mp4Why
I just did this to see what would happen, but if it worked a bit better I can think of a couple of interesting applications.
Firstly, it might be an interesting way to lossily-compress images down to almost arbitrarily-small sizes, in a way that retains detail differently (if not necessarily "better") than traditional lossy compression algorithms.
Secondly, it can be used to upscale images in a way that might look more natural than normal interpolation algorithms, because the neural net (presumably) encodes some more abstract information about the shapes in the image, rather than the pixel values.
Potential improvements
I did try reducing the image to black-and-white to see if reducing the amount of work the network had to do would make it train more quickly, but it didn't seem to make a lot of difference. It generated the same kind of images, but in black-and-white.
Also, since the output images are clearly lacking so much detail of the input image, I tried downscaling the input image, on the basis that having fewer training inputs would make the training run more quickly. And it did help, but obviously that's not a general solution.
The neural net has to be quite small because I'm training it on the CPU and it is slow. It would be interesting to see if it would be much better with much larger networks trained on a GPU. I don't know if a larger network would actually help that much. I still think my network with 3*15*3 hidden nodes could do a much better approximation than what I'm seeing, so I think the real limitation is in the training method, which GPU speed would also presumably help with.
Finally, I think it would be interesting to try training it with a genetic algorithm instead of with backpropagation. You'd maintain a population of candidate weightings for the network, and at each generation you evaluate each candidate for fitness, and then breed the best handful together by repeatedly selecting weights from 2 "parents" to produce 1 "child", with a small amount of mutation (and maybe even some backpropogation training!), to go into the next generation's population.