
4.40am. The alarm wakes me up, but I was pretty much awake already. I get out of bed, put on my dressing gown, make a cup of tea, and sit down at the computer. I warm up my fingers with a few rounds of 10fastfingers. I open up vim and type out my template: #!/usr/bin/perl, use strict; use warnings; while (<>) { chomp; }. I drink a sip of the tea and wait for the clock to tick down. 4:59:40. Almost time. My heart races. 4:59:55. I hover the mouse cursor over the number 22. 4:59:58. Why is time passing so slowly? The wait is agonising. 5:00:00. Finally. I click the left mouse button and off we go. Day 22 part 1: Crab Combat. The next 4 minutes and 58 seconds pass in a furious blur of reading, thinking, and typing. I submit my answer. 158th place. Gah, close. On to part 2. More reading, thinking, coding, debugging, until at 5:22:55 I submit my part 2 answer. 139th place. 0 points. Better luck next time. I browse Hacker News and /r/adventofcode for half an hour while the adrenaline wears off, and then go back to bed.
This has roughly been my routine for the past 25 days. I've been competing in Advent of Code, which is an annual advent calendar of small programming puzzles. Each puzzle is released at midnight EST, which is 5am GMT. Each puzzle (except day 25) consists of 2 parts, but you don't get to see what the second part is until after you've solved the first.
Advent of Code's creator, Eric Wastl, says that it's not strictly a programming competition, that it merely has just enough affordances that those who want to treat it like a programming competition can do so. Specifically, the first 100 people to solve a part 1 or a part 2 receive points based on their rank: 1st gets 100 points down to 100th who gets 1 point. The overall leaderboard shows the points and ranks of the top 100 participants.
According to the stats page over 155,000 people have submitted a correct solution to day 1 part 1, although obviously the vast majority are not treating it as a competition.
Results
I did some of Advent of Code last year, but didn't start until day 12 and didn't reliably get up at 5am to do it. I ranked on the daily leaderboards a couple of times, which was exciting, but really I was only doing it for fun. This year I started out only trying to beat my friends, but after a 10th place on day 6 part 1, and points scored for both parts of day 7, I was sitting 54th on the overall leaderboard! 46th place on day 8 part 2 bumped me up 2 more places, to 52nd overall, and from there I started taking the competition quite seriously.
Then followed a bit of a dry spell, and after day 13 I was sitting in 96th place, only 12 points away from dropping off the leaderboard. Day 14 was my best day of the competition, scoring 165 points with 13th on part 1 and 24th on part 2. Back up to 66th place. Phew! Safe again, for now.
After day 19 I was down to 94th place, but 29th on day 20 part 2 bumped me back up to 83rd. 0 points on day 21, I dropped to 85th. 0 points on day 22, I dropped to 88th. On day 23 I scraped 11 points from 90th place on part 1, but still dropped down to 90th overall. 0 points on day 24, I dropped to 96th place. And finally I scored 0 points on day 25, finishing the competition with 585 points and 103rd place.
Although I had a lot of fun during the competition, this ending was a pretty crushing defeat. After 18 straight days in the top 100 on the overall leaderboard, I was now permanently off the 2020 leaderboard. Just another one of the 155,000 who don't get their name in lights.
The person in 100th place on the leaderboard scored 588 points, only 3 more than me. I worked out that if I had solved days 7 and 8 one second faster, and day 6 three seconds faster, then I would have bagged the 4 extra points to take 100th place. My defeat came down to just 5 seconds of programming time.
Obviously, from a certain perspective, 103rd place in a global programming competition with arguably 155,000 entrants is a great success, but I can't help feeling an enormous sense of loss from missing out on the overall leaderboard by so little, and falling off it on the very last day.
I probably won't be doing Advent of Code again next year, because getting up in time for 5am every day is very annoying (although this is made easier by the fact that there is a coronavirus going around and I therefore no longer have any social obligations).
Advent of Code vs other programming competitions
Most of the Advent of Code problems are a lot easier than most programming competition problems, so if you have taken part in other programming competitions and found the problems too hard, Advent of Code might be for you. The other edge of that sword is that implementation time is critical, and seconds count. On the easier problems there simply isn't time to properly read the problem statement, you need to skim it as fast as you can and assume that the problem is whatever seems most likely based on the few keywords you managed to pick out. I would definitely recommend practising on previous year's problems to get the hang of the kinds of things that come up, the format of the questions, and so on.
Quite a lot of people record video of their solving and post it on YouTube. I recommend watching Jonathan Paulson, he finished 15th overall this year.
A lot of programming competitions are graded with spoj or DOMjudge. In these competitions you submit your program, and the system automatically runs your program against a collection of (secret) input sets, and decides whether your program passed or failed. This would not be suitable for Advent of Code because of the sheer number of participants. For Advent of Code you are given an input set and have to produce the corresponding output. This drastically changes things, in a way that I like, because it means you're no longer constrained to solving the problems with programming. You can solve them by hand, you can use a spreadsheet, you can use online tools, or any combination. You're only graded by how quickly you can produce the final answer.
The idea of having part 2 hidden until after you've solved part 1 simulates the changing requirements encountered in real-world programming tasks, unlike what you find in most programming competitions. It sometimes helps to write your part 1 solution with extensibility in mind, because it might help on part 2. Although, my view is that you can not predict what the future requirements will be, and it's often easier to extend the code later if it is written to be simple, rather than extensible.
My solutions
I wrote all of my programs in Perl, because it is the best language in the world. (Fight me.)
The Advent of Code problems are designed so that interpreted languages are not at a substantial disadvantage relative to compiled languages, so there's no reason not to use whatever language you're most productive in. I think most of the top of the leaderboard uses Python.
If you want to read the code that I wrote for this year, it's in my aoc2020 repo on github, but note that unlike many Advent of Code participants, I very rarely tidy up the programs after I've got the correct answer, so my programs tend to be pretty messy: I'm targeting implementation speed above almost all else.
I don't know how wise it is to publish code like this on github. I heard of a job applicant who had submitted a proper github repo for a pre-interview code review. The reviewer didn't know the language that this program was written in, so he looked through the applicant's github profile for a project he could understand, found the Advent of Code repo, and rejected the applicant based on how disgusting the code was. Doesn't really seem fair, but if the reviewer didn't understand the purpose of Advent of Code, I can see why he made the mistake. But I probably won't be applying for jobs any time soon so I'm not going to worry about it.
Thoughts on some of this year's problems
Stop reading now if you don't want spoilers.
Day 1: Report Repair [link]
This problem asks you to find 2 entries that sum to 2020 from a list of input numbers, and report their product. A surprising number of people wrote a solution like:
for a in list:
for b in list:
if a+b == 2020:
return a*bFor the size of list given in the problem, this is plenty sufficient (and it is only day 1, after all: it's supposed to be easy), but this solution is unnecessarily O(n2). I prefer something more like:
havenum[a] = 1 for a in list
for b in list:
if havenum[2020-b]:
return (2020-b)*bAssuming havenum is implemented as a hash table (or even an array would do in this case) then this solution is O(n), which means it is suitable for much longer lists of numbers.
Also note that both pseudocode solutions shown above have the bug that they can report 1010 * 1010 if 1010 appears in the input, even if only once! This is a bug that a lot of people - including me - implemented, but it didn't turn out to matter as 1010 was not present in the input. But these solutions are not technically correct.
Day 5: Binary Boarding [link]
This problem asks you to take in a series of 10-letter directions to aeroplane seats and report the highest seat number encountered. The space inside the plane is split up with binary space partitioning, so the first letter of the directions tell you if you're in the front or back half of the plane, the second letter tells you if you're in the front or back half of that half, and so on. It's kind of related to a binary search: instead of finding the position of an element by splitting the space in half at each iteration, you're just directly told the half-space that you need to step into at each iteration. I've already spent plenty of time considering space partitioning schemes like this, and many years ago I published the only documentation I'm aware of for the Sauerbraten map format, which is based on octrees: Sauerbraten map format documentation.
The directions in the problem look something like "BFFFBBFRRR": the first 7 letters tell you which row to go to, and the last 3 letters tell you which seat to use in that row. The problem text explains the mapping of directions to seat numbers (rows 0 to 127, columns 0 to 7 within a row, seat numbers are row*8+col). The "obvious" approach is to implement this like the binary search: take the letter at each position to divide the search space, and report the seat number that is reached at the end.
The trick is that the mapping of directions to seat numbers means you can just directly map F to 0, B to 1, L to 0, and R to 1, and then interpret the result as a binary number (so "BFFFBBFRRR" becomes 1000110111 == 567). I recognised this immediately, but slowed myself down by blundering the mapping (I first had F and B reversed, then realised that mistake and reversed all of the digits, then finally got it right), eventually submitting the correct answer after 5m14s. If I had been smart enough to type the mapping correctly on the first try then I might have scored some points here.
Day 8: Handheld Halting [link]
Implementing virtual machines has been a common theme from previous years of Advent of Code, and this problem looked like it was introducing the start of a new VM for this year, although as it happened this was the only VM-related problem, to the disappointment of many.
This problem specified a very simple (and non-Turing complete) instruction set which supports only 3 instructions: acc adds its argument to the accumulator, jmp is a relative jump, and nop does nothing. The problem input is a program using these instructions. Part 1 asks you to find the value in the accumulator the first time any instruction is executed a second time. This was pretty straightforward, just do what it says: execute the program until any instruction is executed a second time and then report the value in the accumulator.
The problem input would be an infinite loop if left alone, because there is no branching and no way to use the accumulator as a jmp argument, so any program that executes any instruction twice will always loop forever.
Part 2 asks you to change exactly 1 opcode: change a nop to a jmp or a jmp to a nop, such that the program eventually terminates by jumping to a position immediately after its last instruction.
The way to solve part 2 is to try changing each jmp and nop in the program consecutively, until you find the one that makes the program terminate correctly. This is hard because some of the modifications you make result in the program entering an infinite loop. In the general case, to prove that a program is not an infinite loop (i.e. that it will eventually terminate) would require solving the halting problem. But the part 1 solution kind of gives the game away by having you already implement a solution to the halting problem for this particular instruction set, based on the observation that if any instruction is executed twice, the program will loop forever. Part of me wishes the part 2 problem had been a part 1 problem, so that you'd have to figure out for yourself how to detect infinite loops.
Somehow I got 46th place on part 2, although I don't think I had any particular advantage in this one. I must have just got lucky in correctly implementing it faster than others did.
Day 10: Adapter Array [link]
You're given a bunch of power adapters in a bag that you are taking on a plane. Each adapter has some rated output voltage, and needs to be powered by some other voltage that is between 1 and 3 volts lower than the output voltage. I found this problem confusing, because in my world-view, the kind of power adapter that you take on a plane takes in 240v AC and gives out some lower voltage DC. That is, the input to the power adapter is a different type of thing from the output, and stringing them together didn't even occur to me as a thing that you could do. I suspect this problem would be easier for people with no prior understanding of power adapters.
Day 13: Shuttle Search [link]
A lot of people found part 2 of this problem quite tricky, because it requires you to know about the Chinese Remainder Theorem.
(Update: VeeArr points out that there is an alternative solution and that Eric actually intended it to be solved without knowing the Chinese Remainder Theorem!)
I had heard of the Chinese Remainder Theorem before because Robin made us all try to understand it when I was on the university programming team. I didn't actually understand it though, and I thought it would never come up in my life again.
After spending a while trying to solve day 13 using parts of number theory that I did know, I eventually Googled the Chinese Remainder Theorem and realised that it is exactly what I needed. Rather than implement it myself, I just wrote a program to restate the problem in terms of the Chinese Remainder Theorem and then I solved the restated version of the problem using an online calculator.
So I still don't know how to implement the Chinese Remainder Theorem, although I suspect I might be more likely to recognise where to apply it.
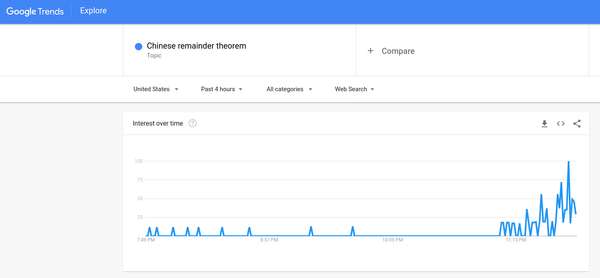
"ch1rh0" on reddit pointed out that the Google Trends graph for "Chinese remainder theorem" on that morning was quite funny:
Day 20: Jurassic Jigsaw [link]
You're given a bunch of tiles that form a jigsaw puzzle. The tiles need to be rotated and flipped and fitted together. Unlike a real-life jigsaw puzzle, you can't immediately tell which tiles go on the edge, because all of the tiles are perfectly square. You fit tiles together by matching the patterns along their edges.
Part 1 asks you to multiply together the ID numbers of the 4 tiles forming the corners of the puzzle. I started out by doing the obvious thing: solve the puzzle, take the ID numbers of the corner tiles, and then multiply them together. Halfway through doing this I realised that you could identify which tiles go at the corners and edges by counting how many of the edges of a tile can possibly be matched with the edge of another tile. The corner tiles are the ones which only have 2 edges which match other tiles.
Part 2 was an absolute bear of a problem. For this part you have to actually solve the puzzle, and then scan the resulting image looking for patterns that look like a "sea monster":
#
# ## ## ###
# # # # # # And then report the number of # in the overall image that do not form part of any sea monster. Also there is no global reference for which way the image is oriented, so you have to attempt this for all 4 rotations, and for each option for mirroring the image. I had some good luck with this, in that I had already written most of the puzzle-solving code for my first attempt at part 1, and managed to write the sea monster-detecting code correctly on the first try, which bagged me 29th place on part 2.
Day 25: Combo Breaker [link]
This problem describes a cryptosystem based on a door and a keycard communicating their public keys and using them to establish a shared encryption key. The problem description is relatively oblique, because it talks about a method of repeatedly multiplying by a number and taking the result modulo some constant, but someone on the subreddit pointed out that it is exactly the same as Diffie-Hellman key exchange, which is quite fun.